一、背景
目前NLP主流范式是在大量通用数据上进行预训练语言模型训练,然后再针对特定下游任务进行微调,达到领域适应(迁移学习)的目的。
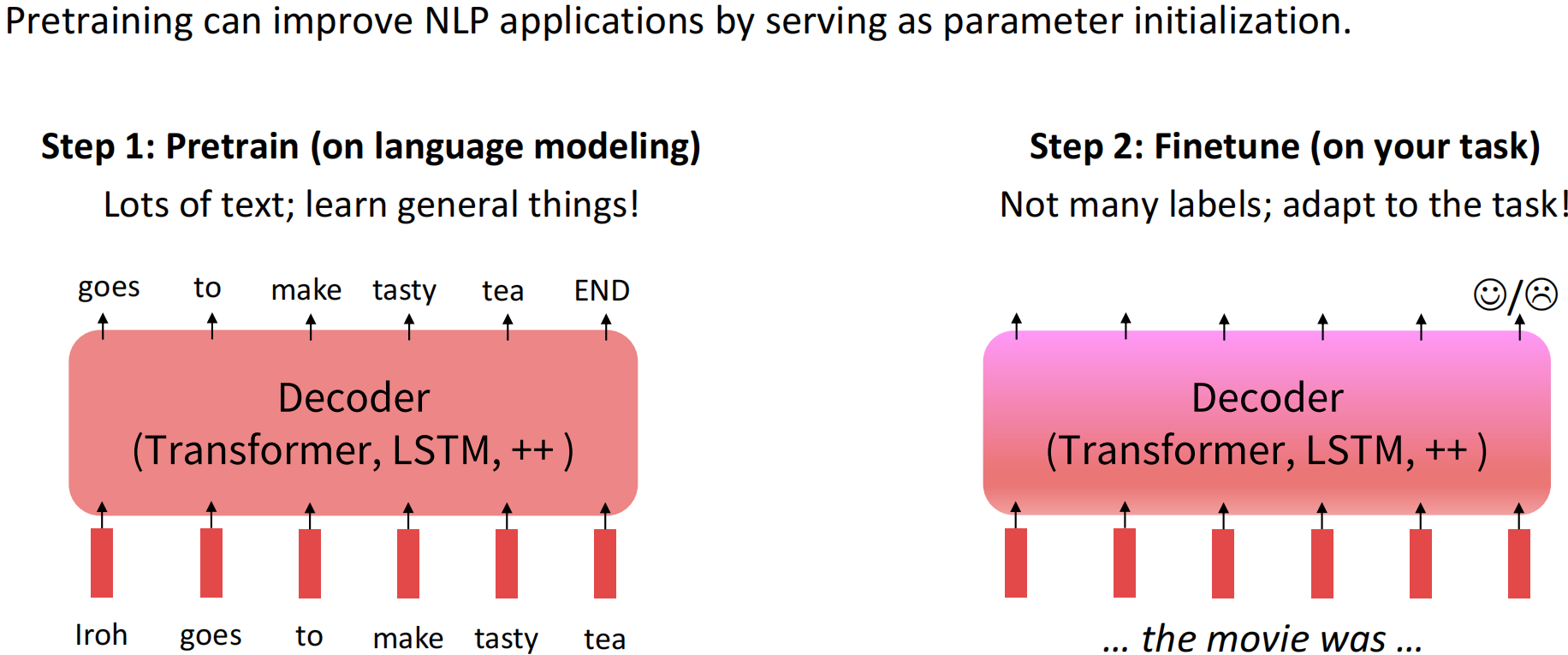
指令微调是预训练语言模型微调的主流范式
其目的是尽量让下游任务的形式尽量接近预训练任务,从而减少下游任务和预训练任务之间的Gap, 实现预训练语言模型适应下游任务,而非下游任务去适应模型。

指令微调的效果要优于基于Zero/Few-shot的提示词工程的上下文学习。
但随着预训练语言模型进入LLM时代,其参数量愈发庞大。全量微调模型所有参数所需的显存早已水涨船高。
例如:
全参微调Qwen1.5-7B-Chat预估要2张80GB的A800,160GB显存(需要确认一下😮) 全参微调Qwen1.5-72B-Chat预估要20张80GB的A800,至少1600GB显存😱。而且,通常不同的下游任务还需要LLM的全量参数,对于算法服务部署来说简直是个灾难
当然,一种折衷做法就是全量微调后把增量参数进行SVD分解保存,推理时再合并参数😓

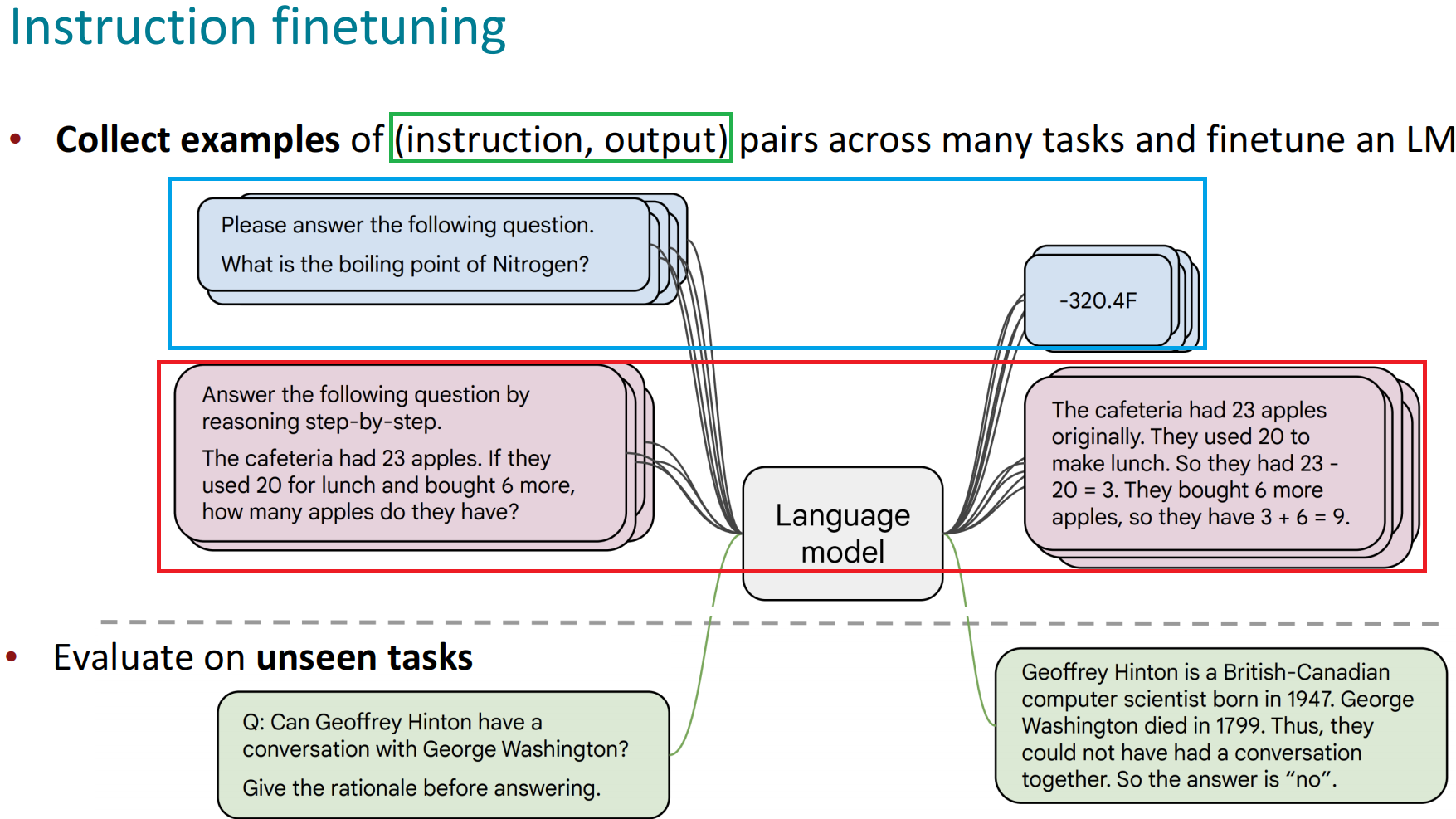
为了寻求一个不更新全部参数的廉价微调方案,之前一些预训练语言模型的高效微调(Parameter Efficient, PEFT)工作,要么插入一些参数或学习外部模块来适应新的下游任务。

接下来将介绍如下4个PEFT方法(重点是主流的LoRA);
Adatper Tuning Prompt Tuning Prefix Tuning LoRA
二、参数高效微调
2.1 Adapter Tuning
Adapter Tuning试图在Transformer Layer的Self-Attetion+FFN之后插入一个先降维再升维的MLP(以及一层残差和LayerNormalization)来学习模型微调的知识。
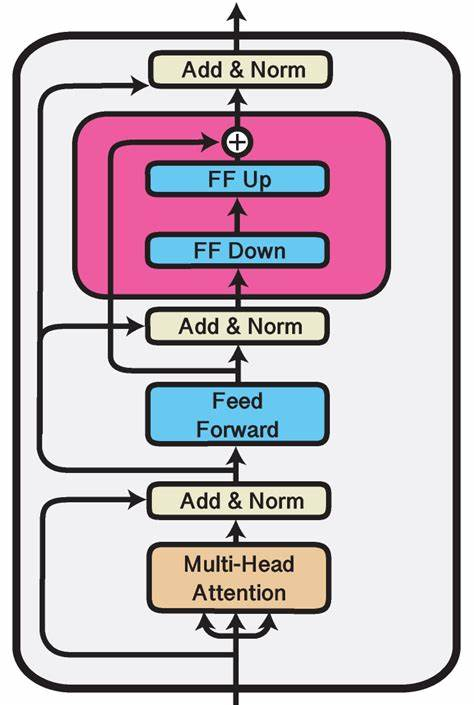
Adapter即插入的FF up + FF Down。

在微调时,Transformer Layer原有的所有参数冻结,反向传播后仅更新Adapter参数。
缺点:需要修改原有模型结构,同时还会增加模型参数量。
2.2 Promot Tuning
https://arxiv.org/abs/2104.08691
Prompt Tuning设计了一种prefix prompt方法,即在模型输入的token序列前添加前缀prompt token,而这个前缀prompt token的embedding是由网络学到。
Prompt Tuning可以看做token已经确定,但是embedding是可以学的。它相当于仅用prompt token的embedding去适应下游任务,相比手工设计或挑选prompt,它是一种Soft的prompt(软提示),

给定n个token组成的输入序列 {x1,x2,…,xT},其对应token embedding矩阵为 Xe∈Rn×d,d代表嵌入维度。
Soft-prompts对应参数Pe∈Rp×d,p代表prompt的长度。
然后,将prompt拼接到输入前面,就能得到完整的模型输入
[Pe;Xe]∈R(p+n)×d 。这个新的输入将会送入模型f([P;X];Θ,Θp),以最大化交叉熵损失来最大化条件概率 PrΘ,Θp(Y|[P;X]),以拟合其标签token序列 Y。在针对下游任务微调时,Prompt Tuning将冻结原始LLM的参数,只学习独立的prompt token参数
参数化的prompt token加上输入的token送入模型进行前向传播,反向传播只更新prompt token embedding的参数
在针对不同的下游任务微调时,就可以分别学习不同的Task Specifical的Prompt Token参数。

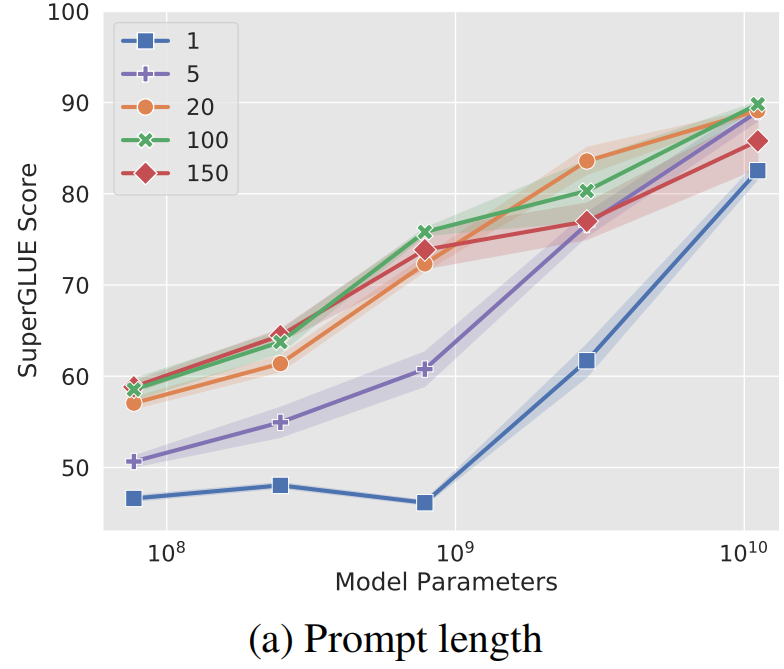
Promot Tuning方法的参数成本是ed,其中de是提示长度,d是token嵌入维度。
提示越短,必须调整的新参数就越少,那么调参的目标是就是找到表现仍然良好的最小prefix prompt长度。
2.3 Prefix-Tuning

为了避免人为的离散Prompt选取优化,Prefix-Tuning提出可学习的Prefix Prompt。

Prefix-Tuning提出可学习的Prompt,即:learns a sequence of prefixes that are prepended at every transformer layer

Prefix tuning为l
层的Transformer Layer的每层多头注意力的键和值都配置了可学习的prefix vectors.
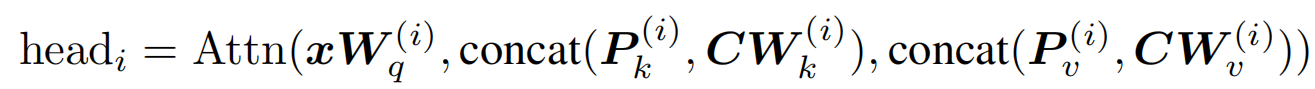
Two sets of prefix vectors Pk, Pv∈Rl×d are concatenated with the original key K and value V
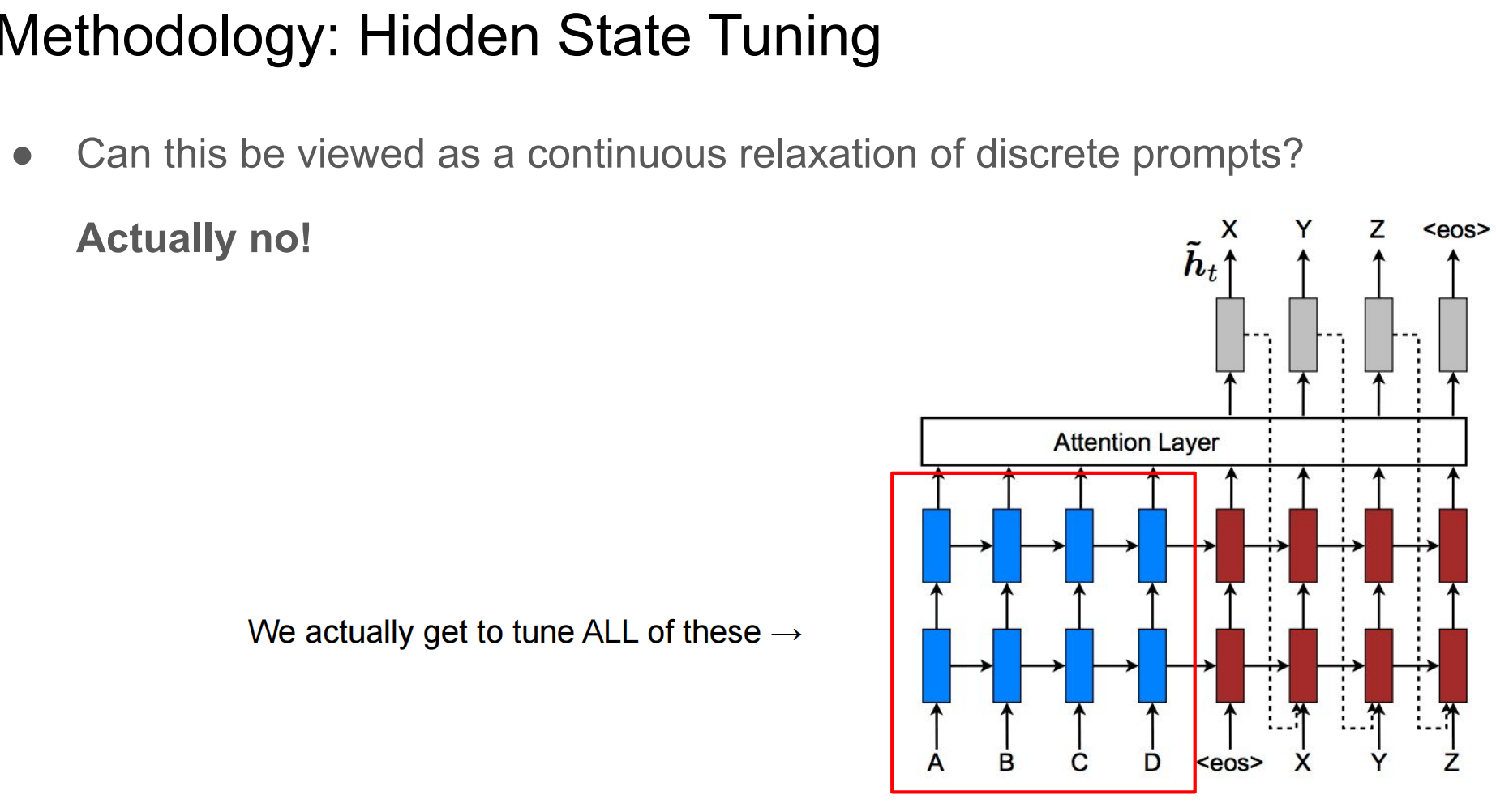
看到这里可以知道,Prefix-Tuning可以算是Promot Tuning的一个特例(Promot Tuning只在输入侧加入可学习的Prefix Prompt Token)
2.4 LoRA
为缓解该问题,LoRA(Low-Rank Adaption of LLMs),即LLMs的低秩适应,被提出用于高效参数微调。
LoRA的核心思想,是假设LLM在下游任务上微调得到的增量参数矩阵ΔW是低秩的
ΔW
是存在冗余参数的高维矩阵,但实际有效矩阵是更低维度的
。
相关论文表明训练学到的过度参数化的模型实际上存在于一个较低的内在维度上
类似于机器学习中的降维算法,假设高维数据实际是在低维的流形上一样
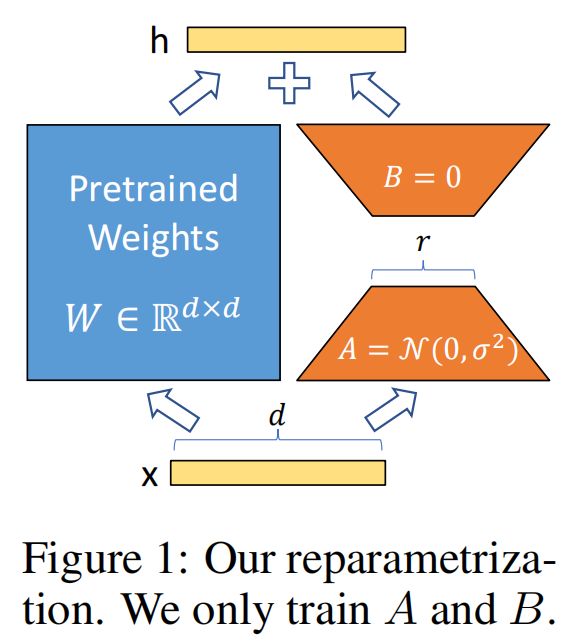
因此,将ΔW=BA用两个更参数量更小的矩阵B∈Rr×d和A∈Rd×r进行低秩近似。
其具体操作是,冻结了预训练的模型权重,并将可训练的LoRA秩分解矩阵注入到LLM的每个
Transformer Decoder层中,从而大大减少了下游任务的可训练参数数量。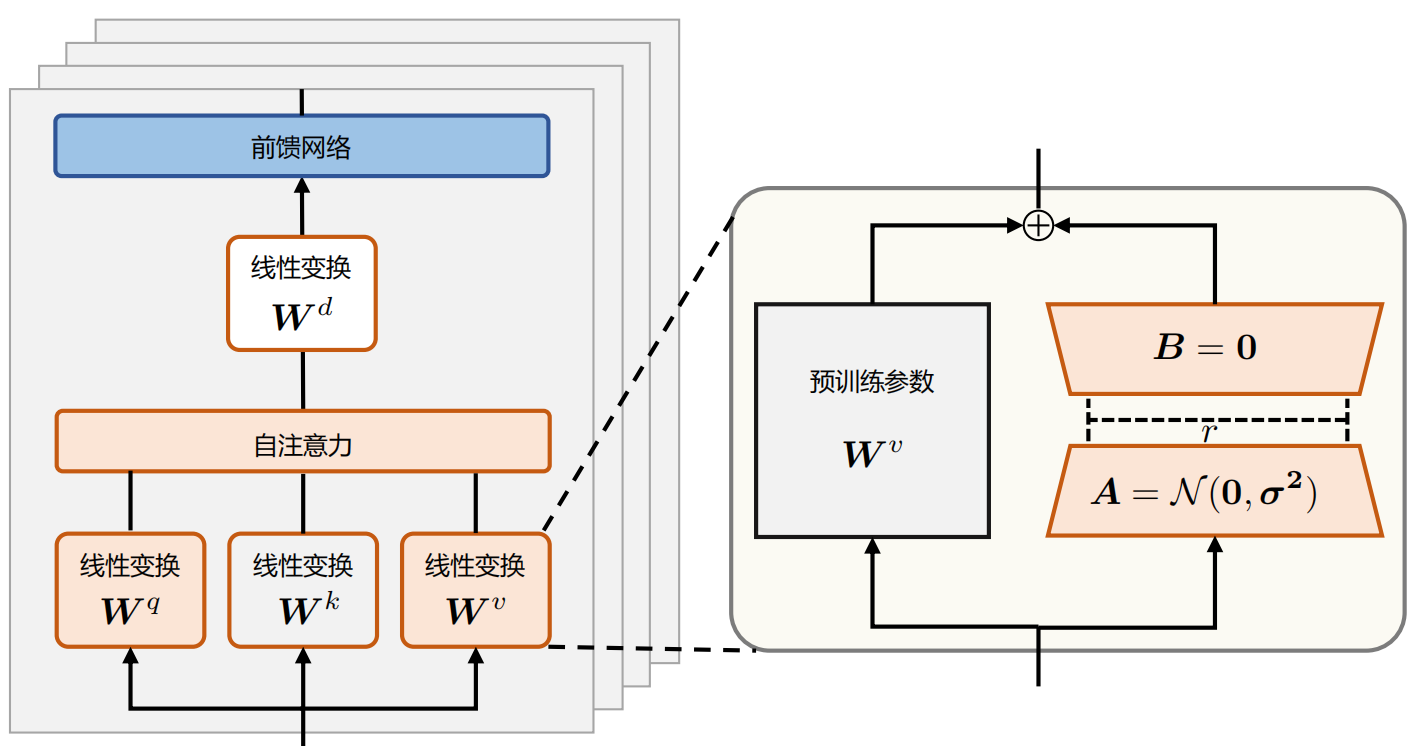
LoRA 方法的计算流程如图对于该权重的输入x来说,输出为下式:
其中,W0∈Rd×d为设预训练权重。初始化时,矩阵 B 通过高斯函数初始化,矩阵 A
为
全零初始化,使得训练开始之前旁路对原模型不造成影响,即参数改变量为0。对于使用LoRA的模型来说,由于可以将原权重与训练后权重合并,因此在推理时不存在额外的开销。
Prefix Tuning是指在输入序列前缀添加连续可微的软提示作为可训练参数。
由于模型可接受的最大输入长度有限,随着软提示的参数量增多,实际输入序列的最大长度也会相应减小,影响模型性能。
三、适用范围
近来LLM主要是指,Decoder-Only架构的大规模预训练语言模型。
毕竟,同等参数规模和训练数据量,Encoder-Decoder架构的T5和Bart在生成任务熵,相比Decoder-Only架构并不具备优势。更不用说,Encoder-Only架构的BERT了。
但是,所有使用Transformer架构的算法都可以使用上述PEFT方法。
针对主流的Decoder Only的生成式因果语言模型,其训练范式具体是:

图片源自:《大规模语言模型:从理论到实践》
预训练(Pretraining):基于海量语料进行Transformer Decoder架构的自回归预训练,拟合语料序列的条件概率分布P(wi|wi,...,wi−1),从而压缩信息,最终学到一个具备长上下文建模能力的超大规模神经语言模型,即LLM 有监督微调(Supervised Finetuning):基于高质量的指令数据(用户输入的提示词 + 对应的理想输出结果)微调LLM,从而得到有监督微调模型(SFT模型)。SFT模型将具备初步的指令理解能力和上下文理解能力(预训练得到的LLM在指令微调的过程中被引导如何使用其学到的知识)
进一步基于结果有排序指令样本, 奖励建模(Reward Modeling):奖励阶段试图构建一个文本质量对比模型(相当于一个Critor)。对同一个提示词,它将对SFT模型给出的多个不同输出的质量做排序。奖励模型可通过二分类模型,对输入的两个结果之间的优劣进行判断。 强化学习(Reinforcement Learning):强化学习阶段将根据给定的提示词样本数据,利用在前一阶段训练的奖励模型,给出SFT模型对用户提示词补全结果的质量评估,并与语言模型建模目标综合得到更好的效果。强化学习微调将在SFT模型基础上,它将使LLM生成的结果文本能获得更高的奖励。除了预训练,增量预训练、有监督微调、有监督微调、奖励建模、强化学习阶段都可以采用PEFT方式。
转载需注明出处 文章首发于知乎:https://zhuanlan.zhihu.com/p/696057719
参考资料
[0] CS224N:Natural Language Processing
with Deep Learning, Sildes (Lecture 11: Prompting, Instruction Finetuning, and RLHF)[1] PrinCETON LLM课程 Sildes(Prompt as Parameter-Efficient
Fine-Tuning)[2] 《The Power of Scale for Parameter-Efficient Prompt Tuning》论文阅读 https://zhuanlan.zhihu.com/p/551174711
[3] Prompt Tuning里程碑作品:The Power of Scale for Parameter-Efficient Prompt Tuning https://zhuanlan.zhihu.com/p/551014127
[4] 图解大模型微调系列之:大模型低秩适配器LoRA(https://zhuanlan.zhihu.com/p/646831196)
[5] Understanding Parameter-Efficient Finetuning of Large Language Models: From Prefix Tuning to LLaMA-Adapters https://lightning.ai/pages/community/article/understanding-llama-adapters/